


whisper
openai 开源的 python 库,提供解析音频文件到文本的功能
https://github.com/openai/whisper
同时也具有将音频文件中的其他语言翻译到英文文本的能力,但是只支持翻译成英文,我的目标是
没有字幕的视频文件(大部分情况下语言是英文) -> 中文字幕
那就需要做一些工作了 😁 具体来说 需要做的是
视频文件 -> 音频文件
音频文件 -> 音频文本
音频文本 -> 字幕(中文)
whisper 只能做第二步,那么我还需要完成第一步和第三步
视频文件 -> 音频文件
ffmpeg 库非常适合处理这种需求,安装后只需一行命令
ffmpeg -y -i 视频源文件 -vn -acodec pcm_s16le 输出.wav
https://github.com/FFmpeg/FFmpeg
我这里统一使用 wav 格式的音频文件
要在 python 代码中使用,可以使用 ffmpeg 的 python 绑定库 ffmpeg-python
https://github.com/kkroening/ffmpeg-python
本质上是封装了一层 python 代码,调用本地的 ffmpeg
转换函数就可以写成如下形式,常见格式的视频文件 mp4、avi 等 ffmpeg 都能支持
import ffmpeg
def convert_to_wav(input_file, output_dir):
os.makedirs(output_dir, exist_ok=True)
filename = os.path.splitext(os.path.basename(input_file))[0] # 去掉扩展名
output_file = os.path.join(output_dir, f"{filename}.wav")
try:
(
ffmpeg
.input(input_file)
.output(output_file, acodec='pcm_s16le', vn=None)
.overwrite_output()
.global_args('-loglevel', 'error') # 设置 ffmpeg 只输出错误信息
.run()
)
return output_file
except ffmpeg.Error as e:
print(f"Error occurred: {e.stderr.decode()}")
return None
音频文件 -> 音频文本
whisper 的 github 仓库提供了一些代码示例
基本使用
import whisper
model = whisper.load_model("turbo")
result = model.transcribe("audio.mp3")
print(result["text"])
进阶使用
import whisper
model = whisper.load_model("turbo")
# load audio and pad/trim it to fit 30 seconds
audio = whisper.load_audio("audio.mp3")
audio = whisper.pad_or_trim(audio)
# make log-Mel spectrogram and move to the same device as the model
mel = whisper.log_mel_spectrogram(audio, n_mels=model.dims.n_mels).to(model.device)
# detect the spoken language
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
# decode the audio
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
# print the recognized text
print(result.text)
阅读文档后,结合我的需求,可以使用简洁的方式,我将默认的模型 base 改为 small
对于转换英文足够使用了,我的 whisper 函数就可以写成
def whisper_basic(wavfile, language="en"):
model = whisper.load_model("small")
result = model.transcribe(wavfile, fp16=False, language=language)
return result
音频文本 -> 字幕(中文)
前面两步做完之后,现在我能得到的是原始视频的音频文本
幸运的是,whisper 解析结果中除了包含文本,还有对应的元信息:文本分块、对应的时间点等等
例如,前面的 whisper_basic 函数返回的数据其实是如下格式
{
"text": "完整的音频转录文本",
"segments": [
{
"id": 0,
"seek": 0,
"start": 0.0, // 指该片段开始的时间,单位为秒。此字段通常用于音频的时间标记
"end": 5.12, // 指该片段结束的时间,单位为秒。表示片段的持续时间为 5.12 秒
"text": "转录的文字片段",
"tokens": [token数组],
"temperature": 0.0,
"avg_logprob": -0.1289,
"compression_ratio": 1.768,
"no_speech_prob": 0.0293
},
{
// ...
}
],
"language": "音频语言"
}
那我就能直接根据这些信息,生成字幕文件,我这里选用目前常用的字幕文件格式 .srt
思路就是循环其中的 segments ,根据元信息生成 srt 文件,函数就可以是
def write_srt_original(result, output_srt_path):
with open(output_srt_path, 'w', encoding='utf-8') as f:
for index, segment in enumerate(result['segments']):
start_time = segment['start']
end_time = segment['end']
text = segment['text'].strip()
# 确保段落不为空
if text:
# 转换为 SRT 时间格式
start_str = format_srt_time(start_time)
end_str = format_srt_time(end_time)
f.write(f"{index + 1}\n")
f.write(f"{start_str} --> {end_str}\n")
f.write(f"{text}\n\n")
return output_srt_path
这一步生成的是英文字幕,我需要的是中文字幕,不过既然有了英文文本,翻译成中文就方便了
改造 write_srt_original 函数,拿到 text 先翻译为中文,再写到 srt 文件中
我这里使用百度翻译的 API,对于认证用户每个月有 100万个字符的额度,代码如下
def write_srt_translate(result, output_srt_path):
with open(output_srt_path, 'w', encoding='utf-8') as f:
for index, segment in enumerate(result['segments']):
text = segment['text'].strip()
if text:
translated_text = translate_by_api(text, target_language='zh')
start_time = format_srt_time(segment['start'])
end_time = format_srt_time(segment['end'])
f.write(f"{index + 1}\n")
f.write(f"{start_time} --> {end_time}\n")
f.write(f"{translated_text}\n\n")
return output_srt_path
调用翻译 API 的代码
"""
基本上都是百度翻译API提供的示例代码 没做太多修改
"""
def translate_by_api(text, target_language='zh'):
# Set your own appid/appkey.
appid = 'YOUR_APPID'
appkey = 'YOUR_KEY'
# For list of language codes, please refer to `https://api.fanyi.baidu.com/doc/21`
from_lang = 'en'
to_lang = target_language
endpoint = 'http://api.fanyi.baidu.com'
path = '/api/trans/vip/translate'
url = endpoint + path
# query = 'Hello World! This is 1st paragraph.\nThis is 2nd paragraph.'
query = text
# Generate salt and sign
def make_md5(s, encoding='utf-8'):
return md5(s.encode(encoding)).hexdigest()
salt = random.randint(32768, 65536)
sign = make_md5(appid + query + str(salt) + appkey)
# Build request
headers = {'Content-Type': 'application/x-www-form-urlencoded'}
payload = {'appid': appid, 'q': query, 'from': from_lang, 'to': to_lang, 'salt': salt, 'sign': sign}
# Send request
r = requests.post(url, params=payload, headers=headers)
result = r.json()
# Show response
# print(json.dumps(result, indent=4, ensure_ascii=False))
# 返回翻译结果
dst_value = result["trans_result"][0]['dst']
return dst_value
然后就是小优化的工作,处理路径,解析命令行参数等
完整代码
import whisper
from whisper.tokenizer import LANGUAGES
import requests
import random
# import json
from hashlib import md5
import ffmpeg
import os
import argparse
def convert_to_wav(input_file, output_dir):
os.makedirs(output_dir, exist_ok=True)
filename = os.path.splitext(os.path.basename(input_file))[0] # 去掉扩展名
output_file = os.path.join(output_dir, f"{filename}.wav")
try:
(
ffmpeg
.input(input_file)
.output(output_file, acodec='pcm_s16le', vn=None)
.overwrite_output()
.global_args('-loglevel', 'error') # 设置 ffmpeg 只输出错误信息
.run()
)
return output_file
except ffmpeg.Error as e:
print(f"Error occurred: {e.stderr.decode()}")
return None
def whisper_basic(wavfile, language="en"):
model = whisper.load_model("small")
result = model.transcribe(wavfile, fp16=False, language=language)
return result
def write_srt_translate(result, output_srt_path):
with open(output_srt_path, 'w', encoding='utf-8') as f:
for index, segment in enumerate(result['segments']):
text = segment['text'].strip()
if text:
translated_text = translate_by_api(text, target_language='zh')
start_time = format_srt_time(segment['start'])
end_time = format_srt_time(segment['end'])
f.write(f"{index + 1}\n")
f.write(f"{start_time} --> {end_time}\n")
f.write(f"{translated_text}\n\n")
return output_srt_path
def write_srt_original(result, output_srt_path):
with open(output_srt_path, 'w', encoding='utf-8') as f:
for index, segment in enumerate(result['segments']):
start_time = segment['start']
end_time = segment['end']
text = segment['text'].strip()
# 确保段落不为空
if text:
# 转换为 SRT 时间格式
start_str = format_srt_time(start_time)
end_str = format_srt_time(end_time)
f.write(f"{index + 1}\n")
f.write(f"{start_str} --> {end_str}\n")
f.write(f"{text}\n\n")
return output_srt_path
def format_srt_time(seconds):
hrs, remainder = divmod(int(seconds), 3600)
mins, secs = divmod(remainder, 60)
millis = int((seconds - int(seconds)) * 1000)
return f"{hrs:02}:{mins:02}:{secs:02},{millis:03}"
"""
基本上都是百度翻译API提供的示例代码 没做太多修改
"""
def translate_by_api(text, target_language='zh'):
# Set your own appid/appkey.
appid = 'YOUR_APPID'
appkey = 'YOUR_KEY'
# For list of language codes, please refer to `https://api.fanyi.baidu.com/doc/21`
from_lang = 'en'
to_lang = target_language
endpoint = 'http://api.fanyi.baidu.com'
path = '/api/trans/vip/translate'
url = endpoint + path
# query = 'Hello World! This is 1st paragraph.\nThis is 2nd paragraph.'
query = text
# Generate salt and sign
def make_md5(s, encoding='utf-8'):
return md5(s.encode(encoding)).hexdigest()
salt = random.randint(32768, 65536)
sign = make_md5(appid + query + str(salt) + appkey)
# Build request
headers = {'Content-Type': 'application/x-www-form-urlencoded'}
payload = {'appid': appid, 'q': query, 'from': from_lang, 'to': to_lang, 'salt': salt, 'sign': sign}
# Send request
r = requests.post(url, params=payload, headers=headers)
result = r.json()
# Show response
# print(json.dumps(result, indent=4, ensure_ascii=False))
# 返回翻译结果
dst_value = result["trans_result"][0]['dst']
return dst_value
def main(file_path):
"""
处理路径 文件名 后缀
"""
# 支持用户目录的 ~ 符号
expanded_path = os.path.expanduser(file_path)
# 将相对路径转换为绝对路径
full_path = os.path.abspath(expanded_path)
# 确保传入的路径是有效的文件路径
if not os.path.isfile(full_path):
print(f"指定的路径无效: {full_path}")
return
# 拆分
input_file_path = os.path.dirname(full_path)
input_file_name, input_file_suffix = os.path.splitext(os.path.basename(full_path)) # 获取文件名和后缀
"""
使用 ffmpeg 提取原始 mp4 文件中的音频为 wav 文件
本质上是在当前系统执行 => ffmpeg -y -i input -vn -acodec pcm_s16le output.wav
"""
print("提取 wav ...")
wav_file_full_path = convert_to_wav(os.path.join(input_file_path, input_file_name + input_file_suffix), input_file_path)
print("生成的 wav 文件路径 =>",wav_file_full_path)
"""
使用 whisper 提取 wav 音频到文本 提供给后续使用
"""
result = whisper_basic(wav_file_full_path, LANGUAGES.get("en"))
"""
根据提取出的 result 直接生成对应的 srt 字幕文件
可以保留作为参考
"""
# print("原始语言的 srt 字幕文件路径 =>", write_srt_original(result, os.path.join(input_file_path, "original_" + input_file_name + ".srt")))
"""
根据提取出的 result 直接生成翻译后的 srt 字幕文件
做法是 遍历解析出来的 result 翻译每一个 segments 中的 text 然后写入 srt 文件
"""
print("使用 API 翻译 ...")
print("翻译后的 srt 字幕文件路径 =>", write_srt_translate(result, os.path.join(input_file_path, input_file_name + ".srt")))
if __name__ == '__main__':
"""
既可以使用 python main.py --fp=path
也能使用 python main.py path
"""
# 创建解析器对象
parser = argparse.ArgumentParser(description="")
# 添加选项参数
parser.add_argument('--fp', type=str, help="输入文件的绝对或相对路径")
# 添加位置参数
parser.add_argument('file_path', nargs='?', type=str, help="输入文件的绝对或相对路径 作为位置参数")
# 解析命令行参数
args = parser.parse_args()
# 确定使用哪个参数(优先使用选项参数)
if args.fp:
main(args.fp) # 使用选项参数
elif args.file_path:
main(args.file_path) # 使用位置参数
else:
print("请提供文件路径")
测试
我使用 uv 管理 python 项目 -> https://github.com/astral-sh/uv
我在 example_file 目录下准备了一个 mp4 文件,目前是英文且无字幕的,用 vlc 打开
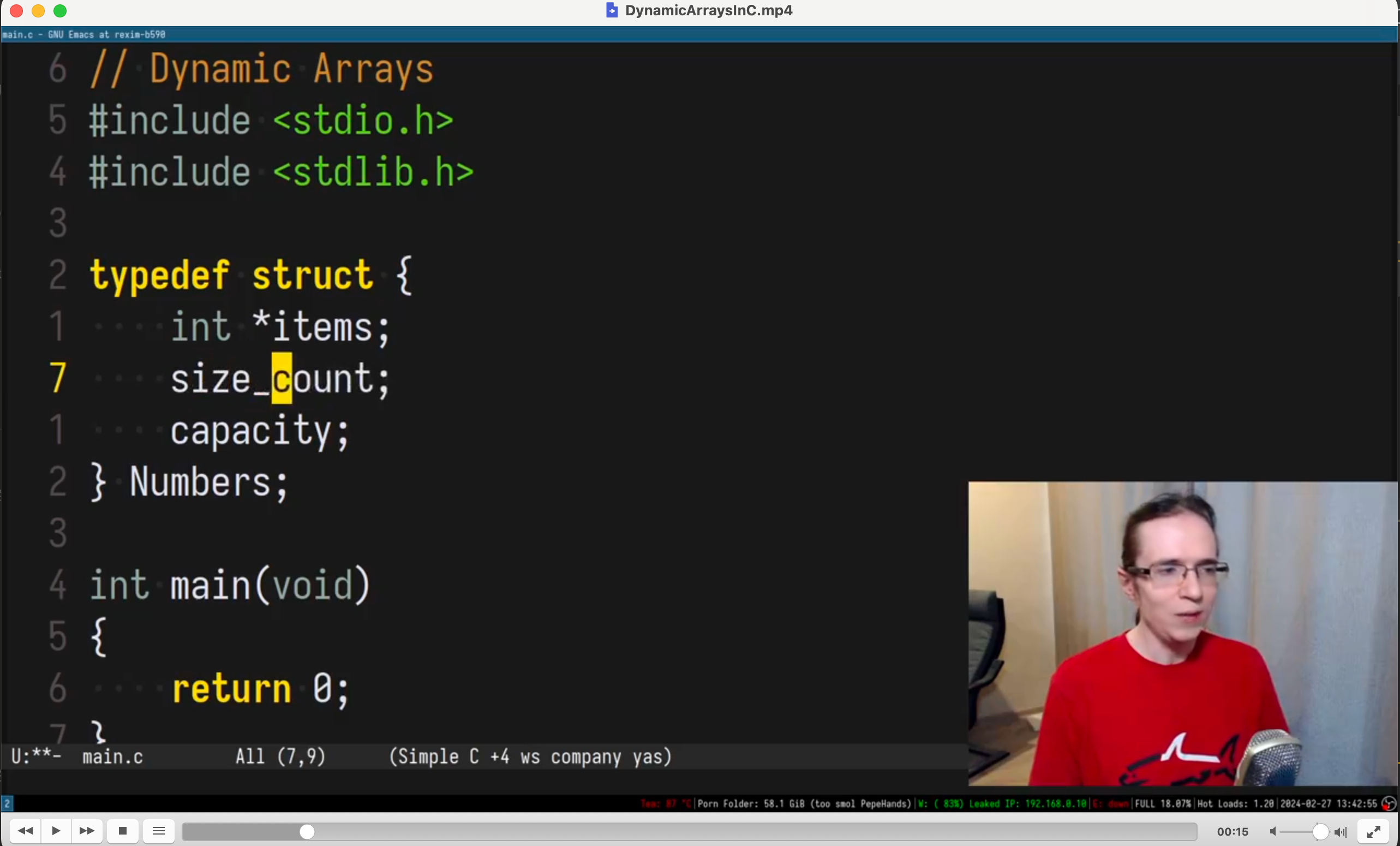
现在使用我的程序生成中文字幕
python main.py ./example_file/DynamicArraysInC.mp4
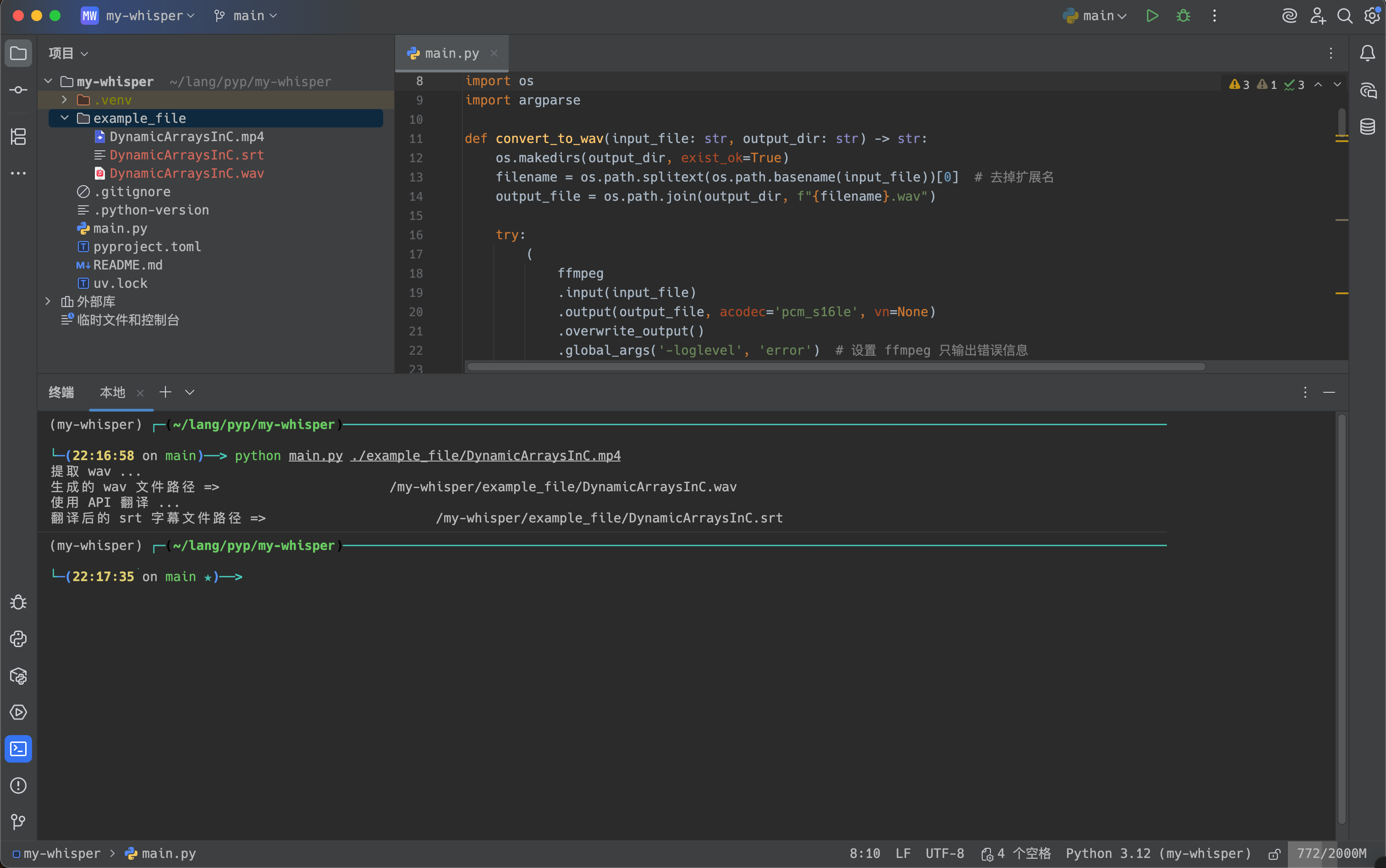
在源文件的同目录下保存了 srt 文件,现在使用 vlc 打开,会默认使用同目录下的字幕文件
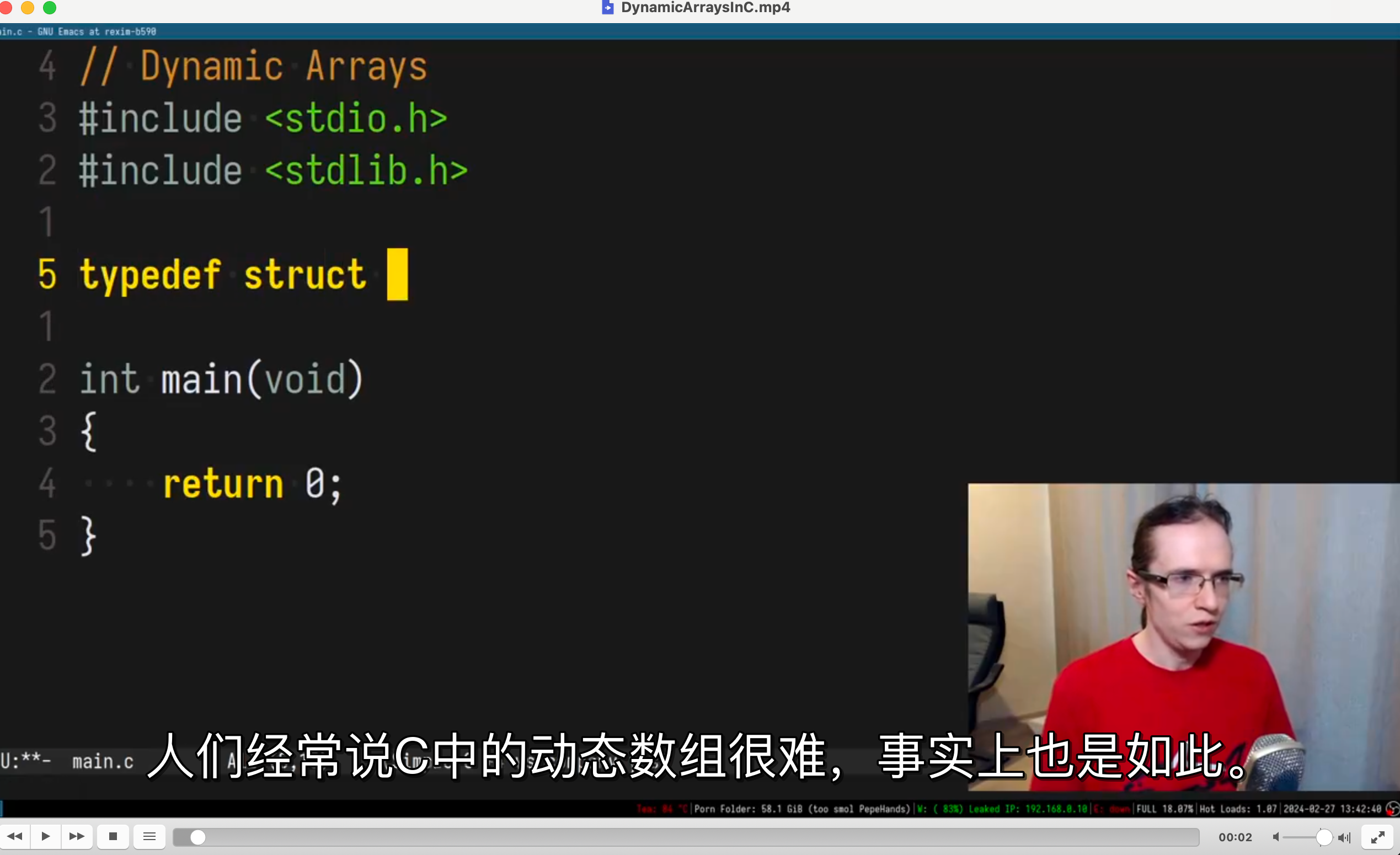
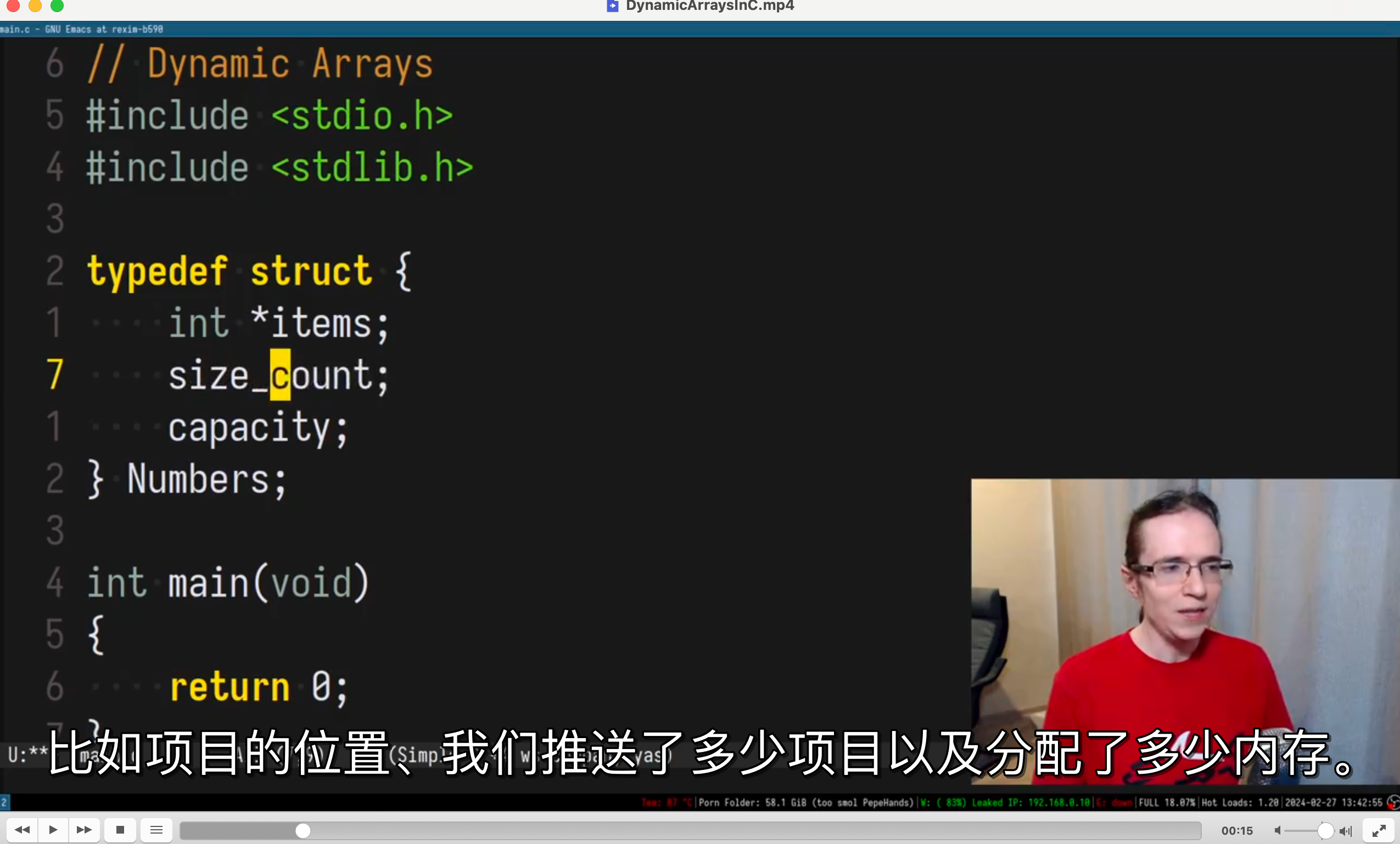
看上去还不错,毕竟我很少写 python 代码,对 python 语言不是很熟悉
翻译的中文准确度取决于 API,有必要的话可以更换 API
并且如果是大文件的话,代码还需要添加针对大文件的处理
例如拆分视频文件、使用多线程处理 😎
评论区